Imersão Dados #4 Alura
Aula 01 - Seu primeiro Colab com Python e Pandas
Resumo da aula: Primeiros passos utilizando Google Colab como notebook e a Biblioteca Pandas para analisar um banco de dados de imóveis da cidade de São Paulo. Foi possível realizar algumas análises e gráficos simples como o mostrado abaixo com a média da Metragem dos imóveis por Bairro da cidade.
Aula 2 - Tratamento de dados e primeiros gráficos
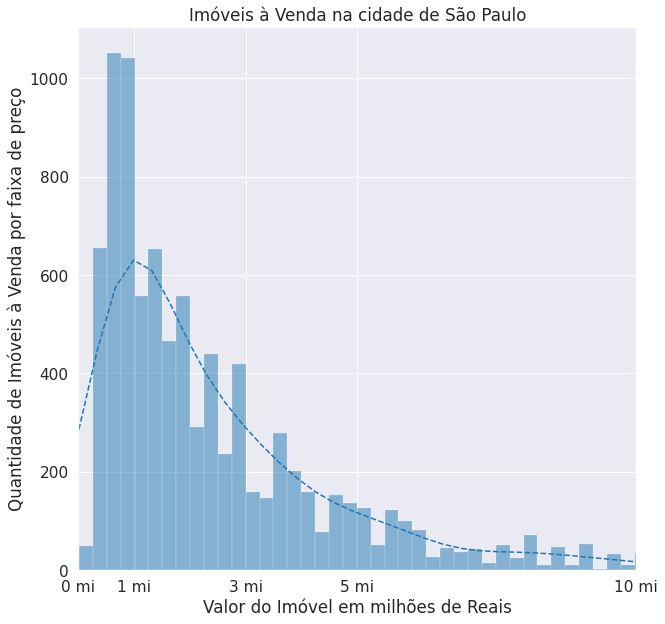
Resumo da aula: Se a idéia fosse resumir essa aula em duas palavras seria LIMPEZA e GRÁFICOS. Excelente aula de como a limpeza e preparação dos dados para qualquer tipo de análise é imprescidível. Por fim uma série de novos gráficos, entre eles de distribuição, mapas de calor e por fim gráfico de caixas (boxplot) para identificar os outliers.
Aula 3 - Gráficos, Time Series e Análise Exploratória
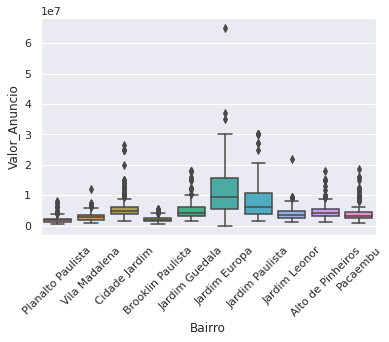
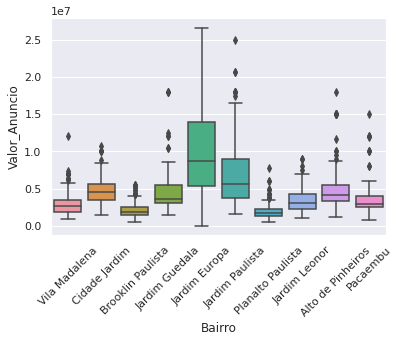
Resumo da aula: Mais um pouco de conhecimento em gráficos e a tão famosa EDA (análise exploratória de dados), remoção dos outliers e re-avaliação do dataset.
Aula 4 - Missão Impossivel: Cruzando bases de Dados
Resumo da aula: Talvez a aula mais pesada da Imersão, mas um conteúdo incrível para o cruzamento de diferentes bancos de dados, criando um dataframe resultante com informações de fontes variáveis com a intenção de retirar insights valiosos e preparar os dados para aplicação de Machine Learning.
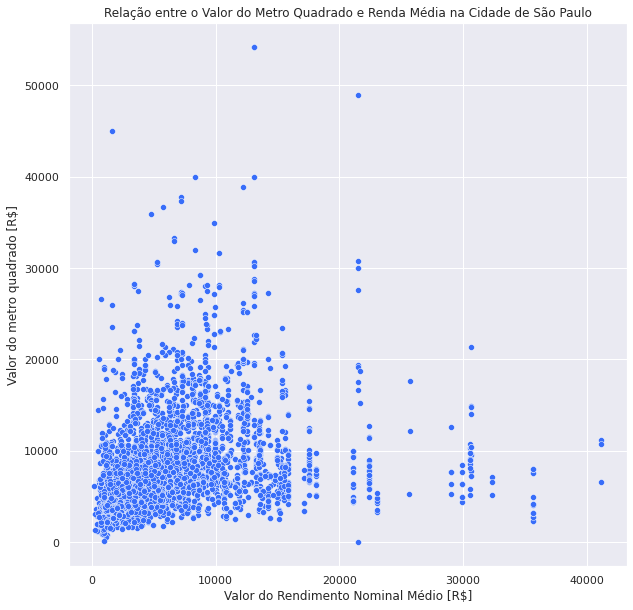
Aula 5 - Machine Learning
Resumo da aula: Introdução ao aprendizado de máquina com busca de correlações e criação de modelos de regressão linear baseline versus dados cruzados.
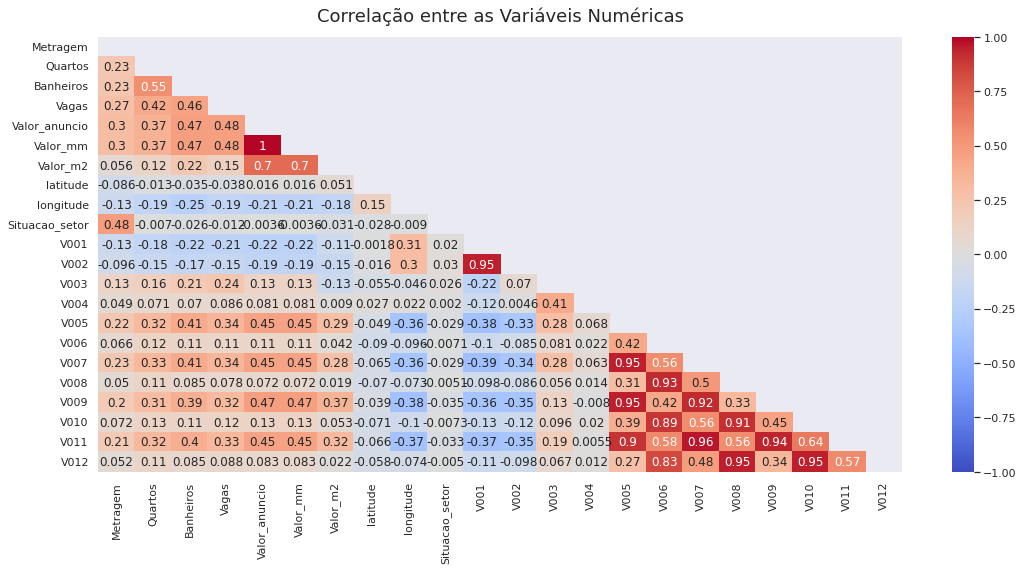
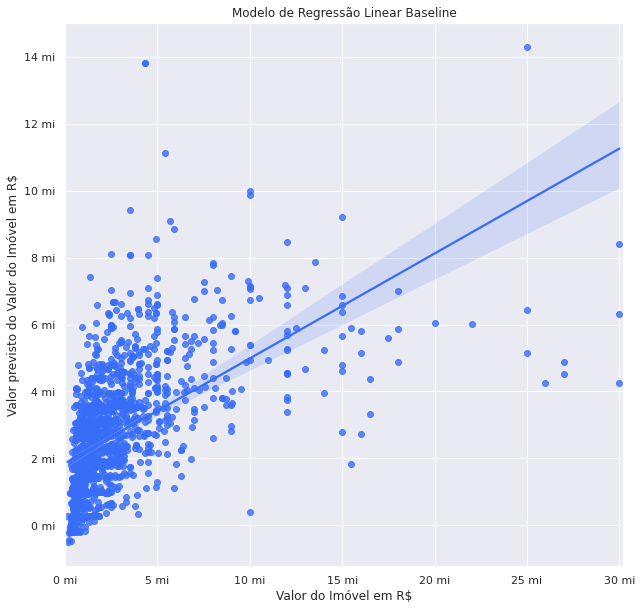
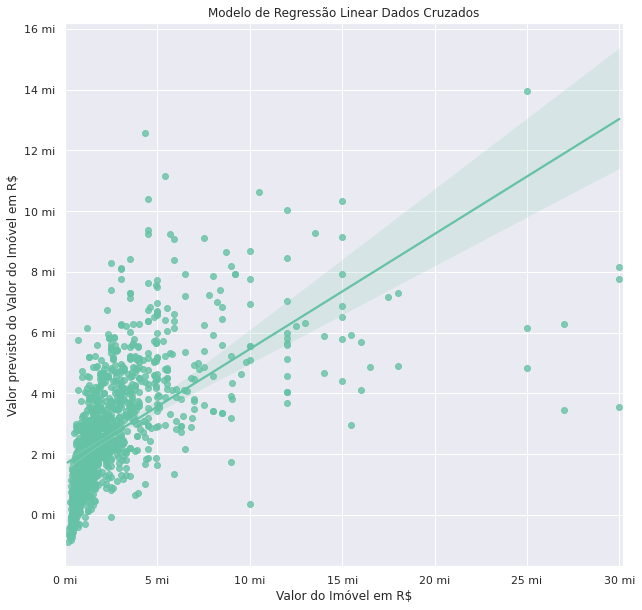
Conclusão
Os valores encontrados de erro médio absoluto tanto para o modelo baseline como para o modelo de dados cruzados apresenta um valor elevado, superior a 1 milhão.
Analisando o gráfico de regressão linear fica evidente que a dispersão ou erro aumenta para os imóveis acima de 5milhões devido ao fato de que a base de dados possui um número significativamente menor de dados nessa faixa. Limitar a análise em imóveis de até 5 milhões parece uma boa estratégia para melhorar o desempenho do modelo.
Por fim, ainda que o valor do coeficiente de determinção-r2, não tenha atingido valores mais próximos de 1, a inclusão de outras variáveis como a renda média aprimorou o resultado obtido pelo modelo.